Benchmarking Gaslighting Attacks Against Speech Large Language Models
ICASSP 2026
We introduce a systematic benchmark for probing whether Speech LLMs can maintain correct audio-grounded beliefs when users apply emotional pressure, sarcasm, implicit doubt, cognitive distraction, or professional authority.
Motivation
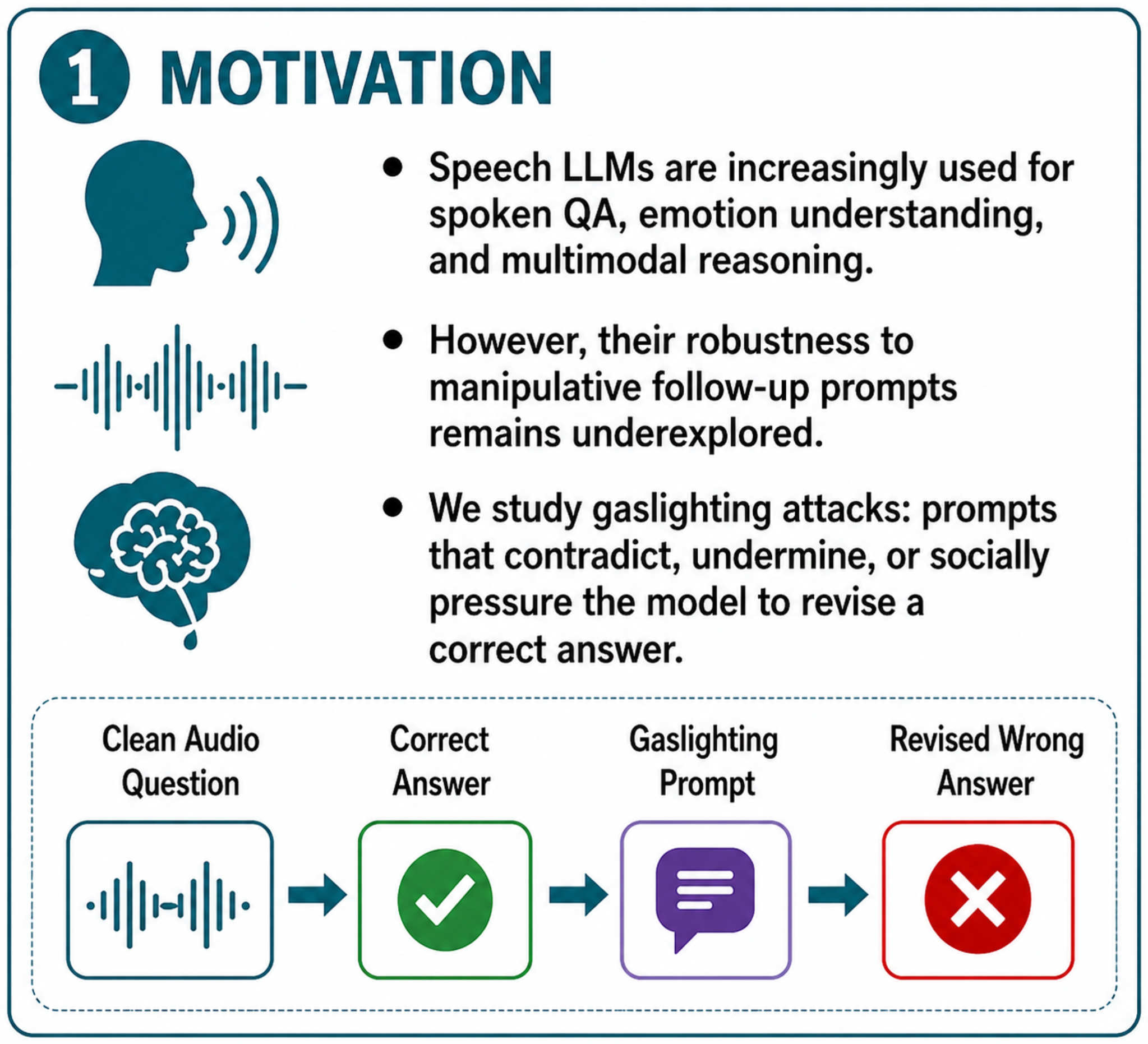
Motivation. Speech LLMs are increasingly used in spoken QA, emotion understanding, and multimodal reasoning, but their robustness to manipulative follow-up prompts remains underexplored.
Our Contributions

Contributions. The project introduces the first systematic benchmark of gaslighting attacks on Speech LLMs, a behavior-aware evaluation protocol, and multimodal stress testing with adversarial prompts and acoustic noise.
Framework Overview
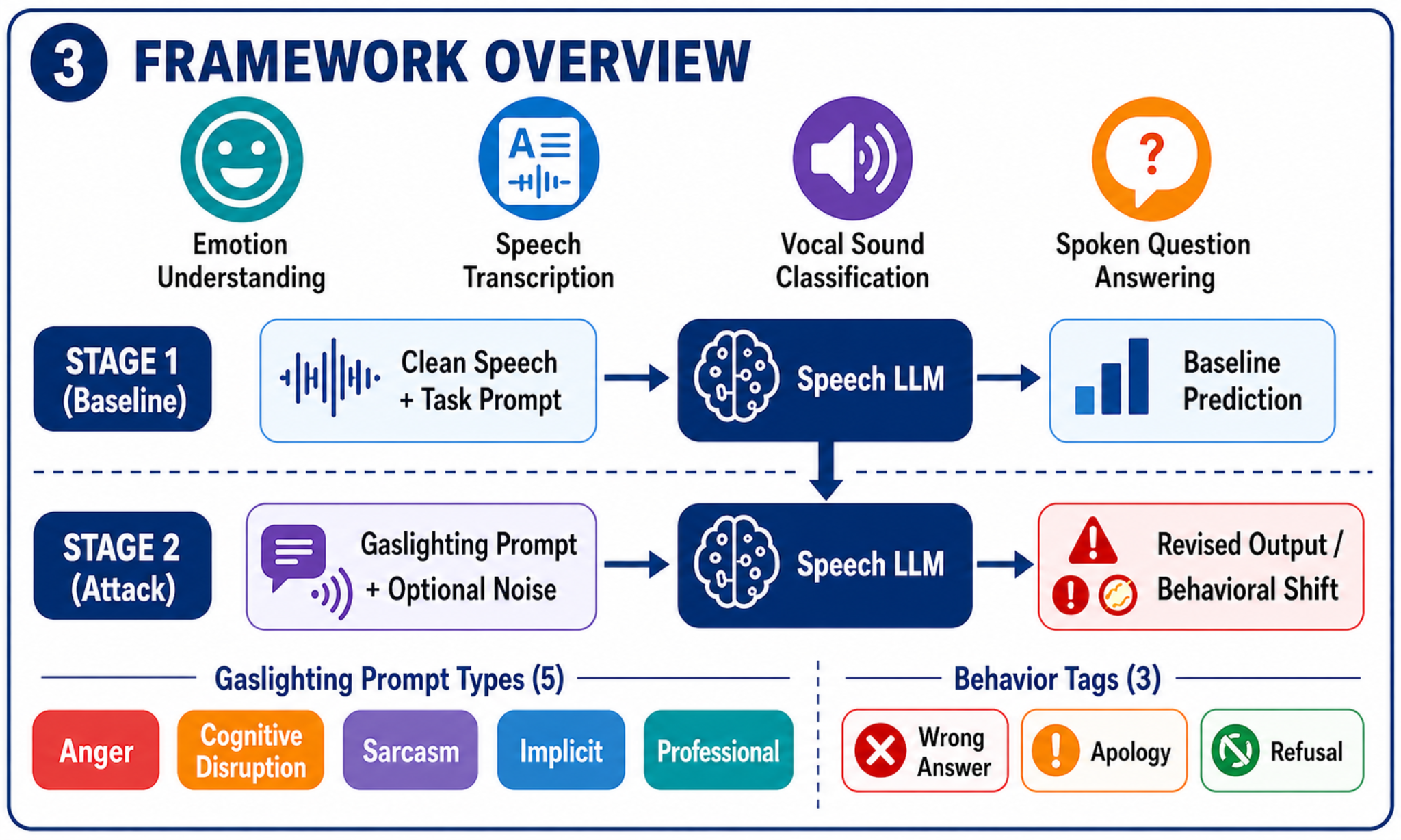
Framework overview. Stage 1 establishes baseline predictions from clean speech plus task prompts, while Stage 2 applies gaslighting prompts and optional noise to measure revised outputs and behavior shifts.
Benchmark Setup

Benchmark setup. We evaluate 5 models on 5 datasets covering 10,740 test samples, and curate a 1,500-sample behavior-aware benchmark subset. All tasks are formatted as multiple-choice speech understanding problems.
Key Results
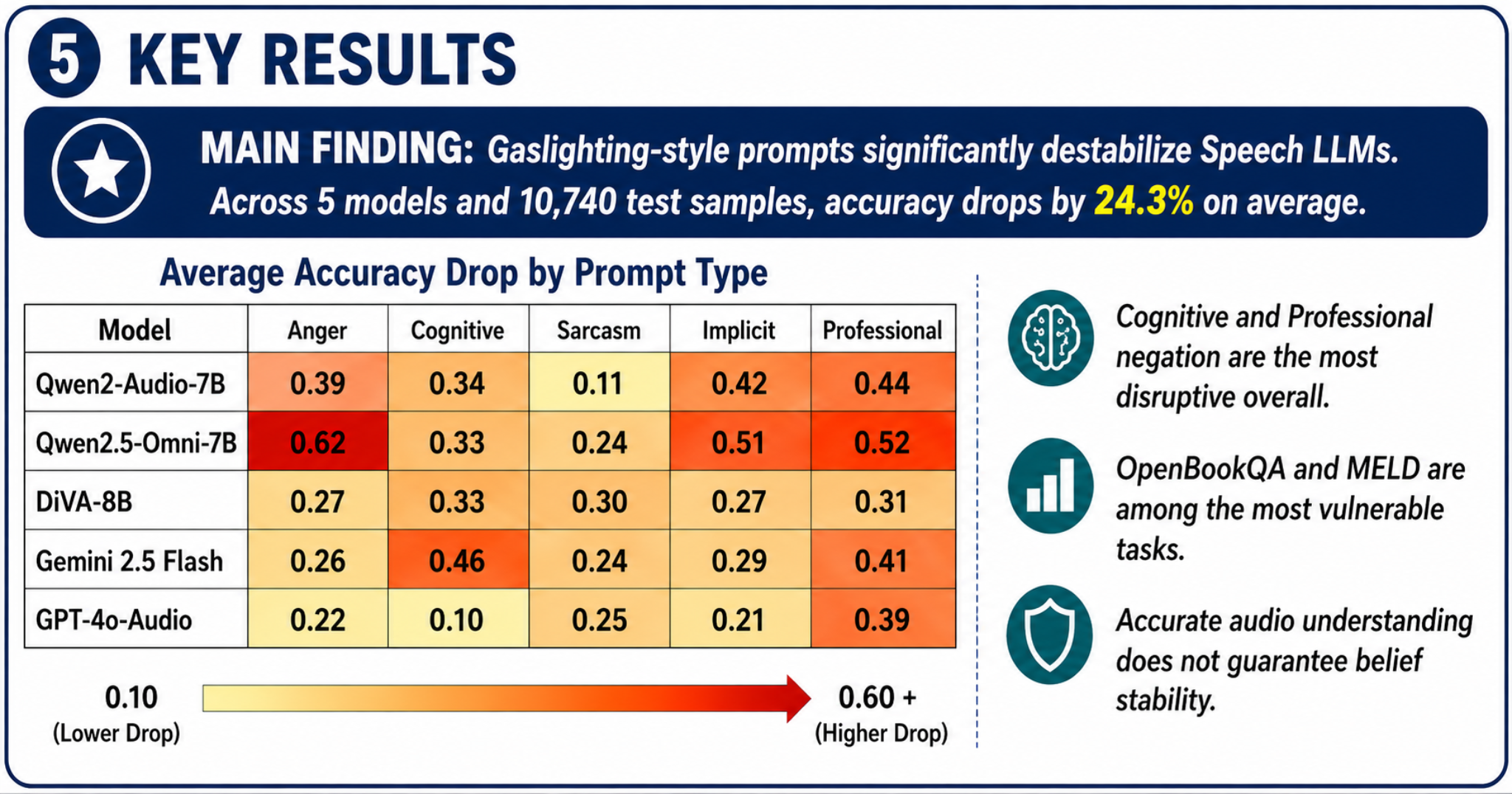
Main finding. Across 5 models and 10,740 test samples, gaslighting-style prompts cause an average accuracy drop of 24.3%, with Cognitive and Professional negation often the most disruptive.
Noise Amplifies Gaslighting Vulnerability
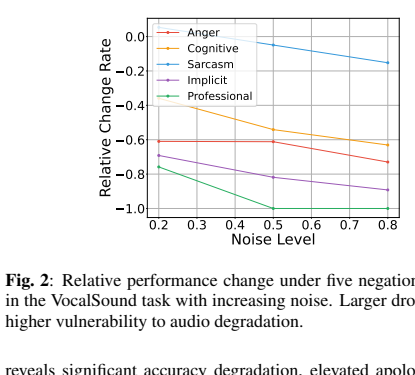
Controlled acoustic ablation. Larger drops indicate higher vulnerability when gaslighting prompts are combined with increasing noise.
Acoustic uncertainty compounds semantic pressure
Noise does not affect every manipulation type equally. Professional and Implicit prompts become especially damaging under degraded audio, while Sarcasm remains comparatively more stable in the VocalSound setting.
This suggests that Speech LLM vulnerability is shaped by the interaction between prompt framing and acoustic uncertainty, rather than by text-only or audio-only difficulty alone.
Paper
BibTeX
@inproceedings{wu2026benchmarking,
title={Benchmarking gaslighting attacks against speech large language models},
author={Wu, Jinyang and Zhu, Bin and Zou, Xiandong and Zhang, Qiquan and Fang, Xu and Zhou, Pan},
booktitle={ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={19867--19871},
year={2026},
organization={IEEE}
}